It works beautiful, but now my bottleneck is when the texture is being applied to the model with .setTexture() call. Once is time to Draw, I guess the problem is uploading the texture to the GPU. It’s fast, but not fast enough to hold real time 24fps (and I would love to have more than 1 texture running uncompressed).
Is there a way to have multiple showbase and share GPU textureIDs between them? so I can paralelize the upload in advance?
Is there any way I can paralelize the preparation/upload of textures? I tried adding it to a task with prepare() but stills chokes once the texture is actually uploaded. Tried use prepareNow() and for reasons already explained somewhere else it crashes (it gets prepared when the main GSG is not active)
I was thinking that maybe I can create a second GSG, do a prepareNow() and then using the TextureContext I can somehow use it in the DefaultGSG.
Does it sounds correct? Or I will get to the same issues? Asking in case the gurus already knows that it would not work and I don’t waste time doing it
I split off your thread since it’s not related to multiple ShowBase instances.
@serega-kkz is talking about async loading from disk. This is supported natively by Panda, but doesn’t seem to be what you’re talking about. (Note that PNMImage isn’t thread-safe, a unique instance should be created for each thread.)
It is possible to do upload of textures asynchronously. There are two ways this is usually accomplished: (1) a separate GSG, with sharing, that is used in a separate thread, and (2) PBOs (pixel buffer objects).
Method 2 is preferred, because it’s more explicit than 1 and it’s easier to set up. However, Panda doesn’t currently support PBOs for upload. You could mess around with using a GSG with explicit calls in a separate thread.
There’s also to consider why your upload is taking long. It could be that the driver is needing to do a conversion step which is making it slow. It may be worth trying different formats or channel layouts.
There is a pending feature request for the async upload on GitHub:
It’s not a lot of work, so if this is blocking you I could see about finding some time to implement this.
I am currently doing a TXO in a multiprocessing.Process with shared_memory.SharedMemory to get back the TXO. It’s not the most efficent but at least I can fully paralelize my TXO creation and indeed is faster to do the Texture().makeFromTxo() that leaves the texture ready.
That being said, it’s not yet doing it as fast as needed, is very close, but it’s taking now 0.03248405456542969 average secs to to the makeFromTxo(). Close enough but does not leave a lot of headroom for other stuff I have to do.
Your post is amazingly informative, at least I know that I was not lost and will try the GSG in a separate thread.
I am sure I am having a conversion somwhere, and that is something I am fixing today. I will create a canvas and work on 4096x4096 textures from now on and I am sure that will speed up the process. Right now, to be honest, I am working with 2-d, 4040 x 2160 pixels, each 3 bytes, rgb which I know might be bringing some overhead/conversion.
All this being said, I just read and informed myself about PBOs… and indeed! That is what would just make it work. With PBOs I could create the external to prepare the textures in TXO and just have a set of threads creating the PBOs a couple of frames in advance. I wish I could help on implementing that in Panda3d core, but that is way ahead of my knowledge
If I find a way to implement the parallel GSG, I will also check timing to find if it’s worthy to create the TXO in the multiprocess spawn or keep just a single .setRamImage() call in the parallel GSG. The problem with that is that I found that the texture is still not being created in advance, but again, with an extra GSG I might be able to use the .prepareNow() which might push it up and then I can share the asset to the main GSG.
The reason why PBOs are efficient is that we can ask for a bit of driver-owned memory, have the application copy data to it in a thread, and then later use that buffer to create a texture with. Without PBOs, the driver needs to immediately copy all the data at texture construction time, which is creating the snag.
I was looking into implementing PBOs yesterday and today but it’s proving a lot more challenging than expected.
Yes, indeed PBOs sound like the way to do it, and how other applications get to handle quick high res texture swap in multiple models/planes for high res image playback.
I cleanup my code yesterday and found there were no benefit of creating the TXO outside the main loop/main application and do a share_memory of it. Getting the memory directly to the texture through Texture().setRamImage() it’s the fastest way to get everything ready for the driver to create the texture, and texture creation (once it happens) seems to be same speed either from memory or from a TXO.
Also, I started studying how to create a second GSG/GraphicsOutput and, in a different thread, create a texture. Then, if I understood the documentation correctly, I use the TextureContext.getTexture() in my main loop to get the texture and swap it to my geometry.
That being said, would the Texture().prepareNow() call in the helper thread would block the driver anyway?.. Well, I guess I will find out once I start playing with it
You need to make sure you get a GSG with shared context. If it’s not using context sharing, then it’s not going to work, since Panda will just reupload the texture for the other context. I haven’t done this myself, so I’m not entirely sure how to make that work. You might also need to create a second GraphicsEngine so you can run that in its own thread.
After reading a couple of times the docs. It seems that yes, I should create a GraphicsEngine in it’s own thread. So I can control renderFrame() (which I guess I need to trigger to generate the texture). What I can’t find (as you mention) is information of shared context. What I will try to see if it’s possible is to share the entire GSG between the GraphicsOutput of two GraphicsEngine(s)
Yeah, not possible to share a GSG between two different GraphicsEngines, I guess it was silly to even try it. I am researching in how to share contexts between GSGs.
I am reading the source code and found in GraphicsEngine.cxx the following line:
// THIS IS THE OLD CODE FOR make_gsg PT(GraphicsStateGuardian) gsg =
// pipe->make_gsg(properties, share_with);
make_gsg would be very useful, but the share_with parameter is what is interesting. Was the GSG sharing deprecated sometime? I will try to dig in old code, but seems that my fail-back option of a shared context instead of PBOs might be not supported as well?
You do need two separate GSGs because you can only use a GSG on one thread at a time.
Hmm, yeah. Normally, Panda creates a shared context automatically when you create a new window, pass in the same GSG but the GSG is incompatible somehow. I think we need to expand the notion of “incompatible” to include “is created with a different GraphicsEngine”, since (as you’ve noticed) you can’t share a GSG between engines.
I thought I had it working with some changes, but I was measuring wrong and I realised it can’t work because both contexts will try to prepare the texture, and one will end up waiting for the PreparedGraphicsObjects mutex. We would need some separate upload queue that is only going to be processed by the other thread’s context and then handed over to the main thread context.
Since this would require more substantial architectural changes than the PBO support, I believe that at this point that is a more viable route to explore.
Understood! Thanks so much for looking into it. It saves me for keep testing something that would never work. Also I agree PBOs is a more elegant way to achieve the uploads.
Again, would love to help but getting that deep into the original source is far from my capabilities. Fingers crossed is not terribly complicated and does not take a lot of your time to try to implement. Meanwhile I will work lowering the resolution on the loading before the uploads or other tricks to try to earn real time while having as high resolution as possible
It is complicated and laborious, unfortunately, but that’s because I’m having to lay a lot of the groundwork for doing this kind of async stuff properly. All this stuff needs to be done sooner or later anyway, though, and it’s going to make this kind of thing a lot easier in the future.
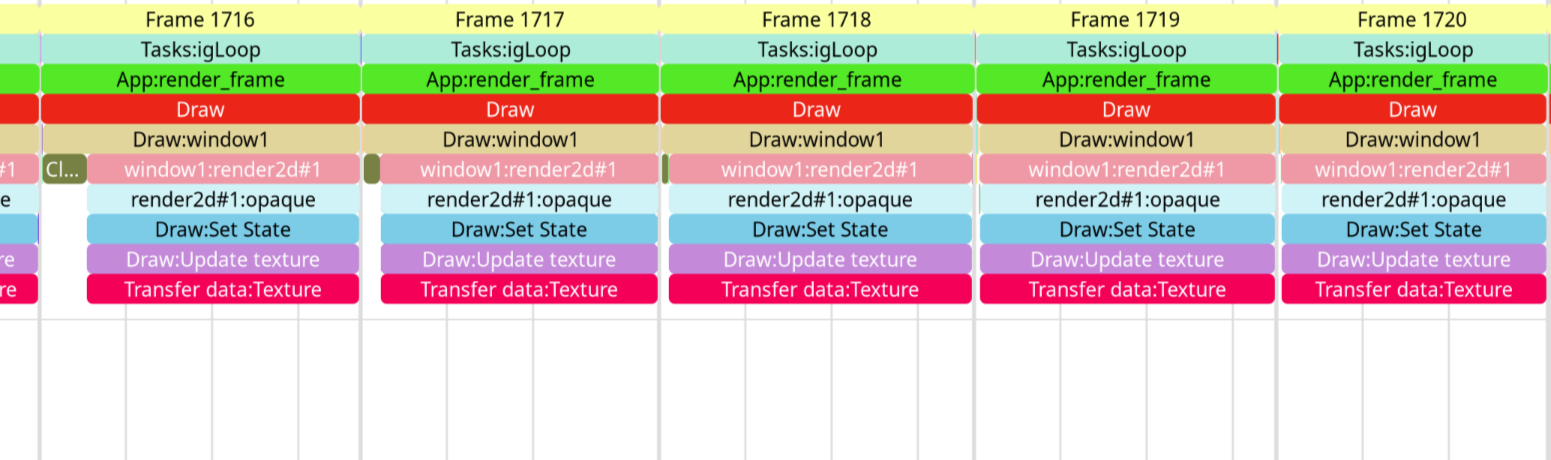
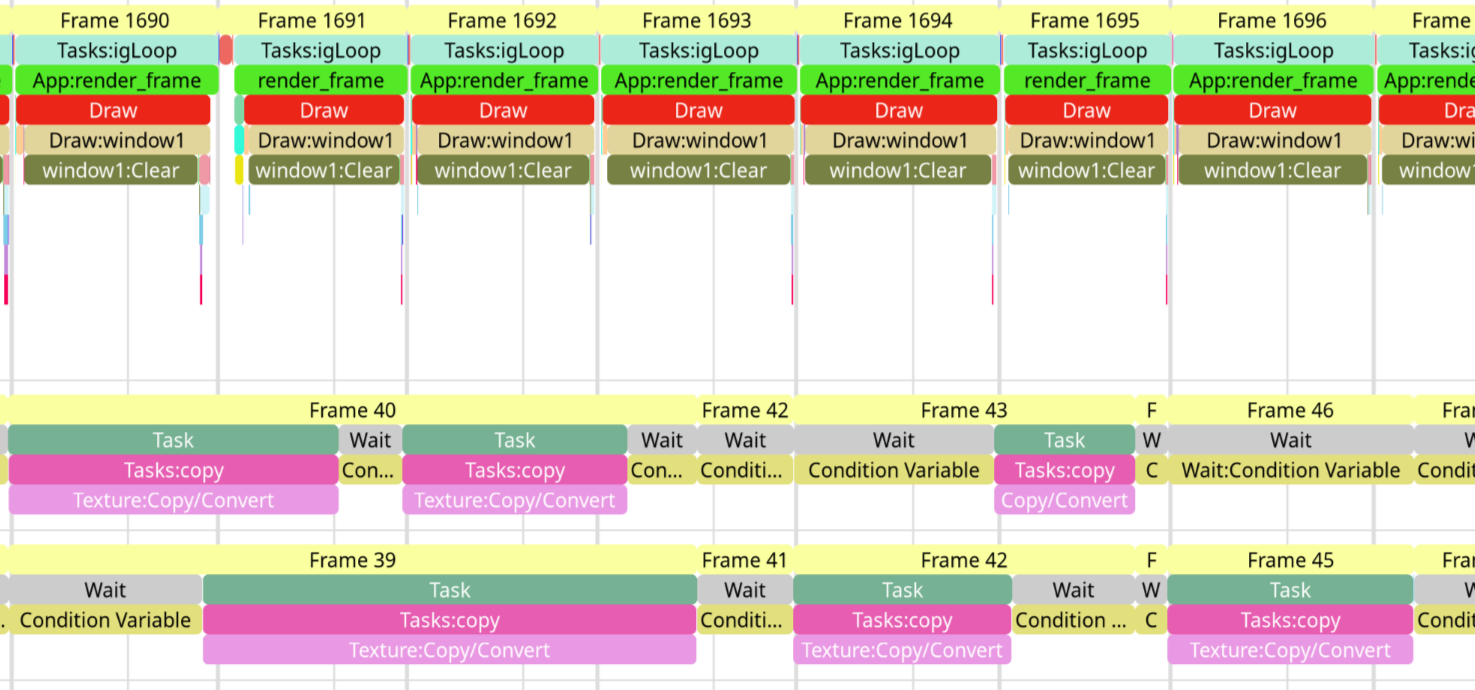
Now that it’s working, though, it works quite well. Here’s the “before”, in synchronous mode, shown in PStats, in an artificial example with an 8192x8192 texture refreshed at 60 fps:
I’m too busy right now to make the finishing touches to the code and give you some more detailed instructions, but if you can’t wait to test what I have so far, what I have is committed to the gl-async-texture-upload branch, buildbot builds can be gotten here, and here is my test code:
from panda3d.core import *
from time import time, sleep
from direct.showbase.ShowBase import ShowBase
FPS = 60.0
SIZE = 8194
NUM_FRAMES = 20
tex = Texture('abc')
tex.setup_2d_texture(SIZE, SIZE, Texture.T_float, Texture.F_r32)
# This is where the magic happens: request 3 buffers to allow up to 3 transfers
# to occur simultaneously. This does mean it uses 4x as much memory!
tex.setup_async_transfer(3)
# Generate 20 unique frames
frames = []
for i in range(NUM_FRAMES):
print("generating frame", i)
tex.set_clear_color((i / NUM_FRAMES, 0, 0, 1))
tex.clear_image()
frames.append(tex.make_ram_image())
card = CardMaker('card')
card.set_frame(-0.1, 0.1, -0.1, 0.1)
base = ShowBase()
base.task_mgr.step()
card_path = base.render2d.attach_new_node(card.generate())
card_path.set_texture(tex)
frameno = 0
def update(task):
global frameno
tex.set_ram_image(frames[frameno % len(frames)])
frameno += 1
return task.again
base.task_mgr.do_method_later(1 / FPS, update, "update")
base.run()
Notably, it’s not safe to modify an existing RAM image (as in, the same PTA_uchar object) when it’s already uploading, but you can assign a new one and modify that fine. I intend to make a change to make it copy-on-write the RAM image automatically if it’s currently being read by an upload thread.
prepare() doesn’t quite do the right thing yet, working on that; right now it just starts the upload as soon as the texture comes into view.