As I keep doing detective work to find memory leaks, I found a funny issue.
My app uses this amount of memory before loading a big 4k texture:

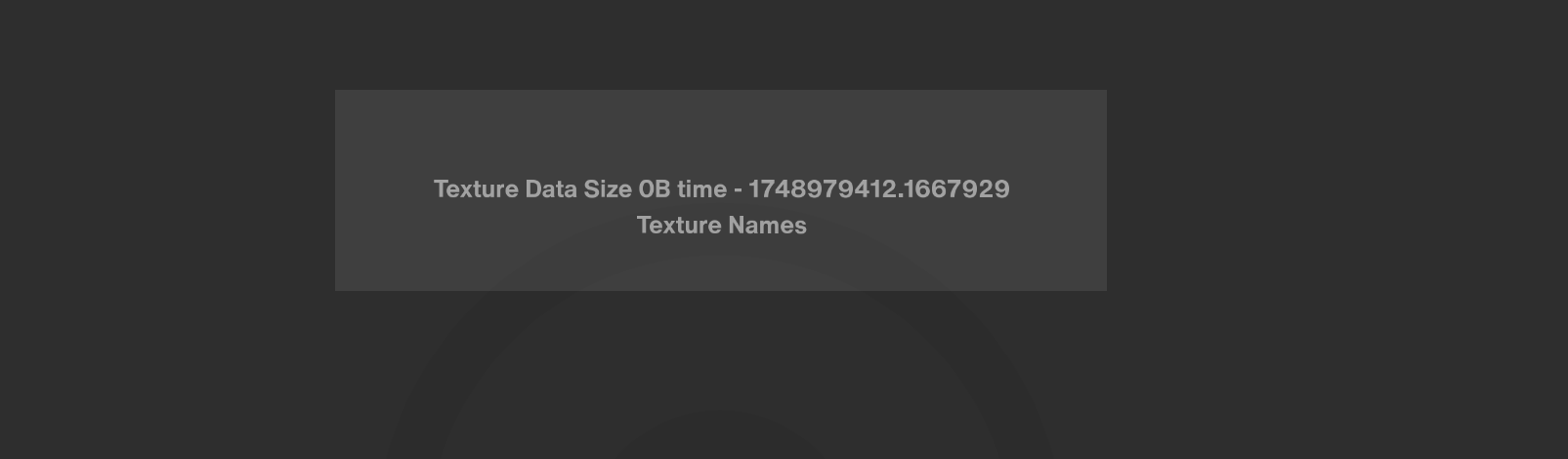
If I report in the app the amount of texture Memory (and texture names) using .getPreparedTextures() from the GSG (and then .getResident(PGO) in the texture) everything looks clean and nice.
I have to do this because pstats (at least on macOS, I have to yet test in Windows) does not work with .setup_async_transfer() when the value is > 0… will get back to this later
If I load a texture with the following parameters:
textureVariable = Texture(layerName)
textureVariable.setup2dTexture(width, height, textureType, Texture.F_rgb)
textureVariable.setup_async_transfer(0)
textureVariable.setKeepRamImage(False)
textureVariable.set_ram_image(imageMemory.buf[:textureVariable.ram_page_size])
asyncVariable = TextureVariable.prepare(GraphicsStateGuardianBase.getDefaultGsg().prepared_objects)
Everything looks nice and it loads great.
And Memory looks and reacts as expected,

If I remove the texture with:
textureVariable.release_all()
textureVariable.clear()
I get a reasonable cleanup size, but most important, is consistent and it does not increase over time:

And inside the .step() is reported correctly that the texture is not prepared.
(I mean, there is a 3 bytes somehow even if I get the textureVariable = None, but I guess that is fine.
If I repeat the process 10-20 times the report of the memory in the OS is, again, consistent, and at some point even it cleans back
Now… For the interesting part:
If I do the same but with:
textureVariable.setup_async_transfer(1)
There is no cleanup of memory when I erase. Actually the memory increases in similare in size with what the expected_ram_image_size is reported:
First load-erase:

Second load-erase:

Third load-erase

And so on until the app starts swapping like crazy.
And is hard to analize, as when I tag any texture with the .setup_async_transfer(1) the pstats application freezes. I tried to find the code for 1.11.0 (using dev3702) to see if I can find something, but can’t get to the source in github (or at least don’t know where to look for it).
Am I missing something on the cleanup of the asyncs? I can’t find any way to garbage collect async usage.
I have tried gc.garbage and cleaning up the pools etc. Even if I remove the ShowBase instance the memory is still there somehow… Until I close the app.
Thanks as always!