This is an impressive renderer addition for Panda3D, there’s no argument there. But I wonder why this hasn’t had the impact it seems it should have properly had on how we’re actually building games in Panda.
For me personally, I find the interface somewhat overdesigned. A significant amount of the pipeline is setup code. The interface does not feel quite native. It is also, unfortunately, rather slow with more than a few options turned on.
The 1.11 roadmap of the official Panda3D engine has a number of physically-based features on it, which is exciting, and I am happy about all the features listed on the 1.11 roadmap. 1.11 Roadmap · GitHub
At this point I’d just like to offer one perspective on how we apply shaders inside an actual game. I’d like to be able to do the following:
Apply from a list of built-in shaders which roughly match the “RenderPipeline” or whatever is actually practical to offer as built-in shaders:
– such that we’re using an entirely text-based way to tell the shader processing system what we want it to combine for a particular node, or the whole scene. I’m not 100% on the implementation details of this, it’s rather more complicated than I suggest of course. But I would personally prefer this kind of setup control over having to build and maintain such a huge architecture as the aforementioned ShaderPipeline.
Does anybody disagree with this idea as a setup strategy? I’d be happy to hear ideas about this.
I’ve slightly reworked the RenderPipeline, removed almost all unnecessary dependencies, however I still need to understand the logic behind it. I’ve put it on hold for now.
Example of how to use my option:
import sys
sys.path.append('../render')
from panda3d.core import loadPrcFile
loadPrcFile("rpconfig.prc")
from direct.showbase.ShowBase import ShowBase
from rpcore.render_pipeline import RenderPipeline
class MainApp(ShowBase):
def __init__(self):
ShowBase.__init__(self)
self.render_pipeline = RenderPipeline()
# "ao fxaa motion_blur bloom color_correction forward_shading pssm scattering skin_shading sky_ao smaa ssr env_probes"
self.render_pipeline.plugins_used = "bloom dof ..."
self.render_pipeline.create(base)
self.render_pipeline.daytime_mgr.time = "8:30"
# ------ End of render pipeline code, thats it! ------
# Load the scene
model = self.loader.load_model("scene/Scene.bam")
model.reparent_to(self.render)
MainApp().run()
I have gone as far as to construct my own daytime/nighttime temporal system and threading support for the “rpcore.render_pipeline” RenderPipeline. It’s interesting to see that you have gone through preliminary work yourself.
I’d rather not have to build it in it’s current state for an official demo with the current state of the 1.11 roadmap, if such a built-in proposal as the original post is possible within a certain time.
Keep in mind that RenderPipeline isn’t just “shaders”. It’s, well, a pipeline, with many preprocessing and postprocessing rendering steps all with their own shaders and rendering techniques. That’s why there’s so much set-up: it’s not a matter of simply applying a few shaders, but most of it is configuring all the different rendering passes and connecting them up in a way that remains configurable. On top of that, it uses its own lighting system that is compatible with its deferred rendering approach.
We have done a lot of brainstorming on how to handle complex rendering pipelines. I do agree there should be a relatively plug-and-play way to do this, but this is way out of reach for 1.11 (or 1.12 for that matter). For what it’s worth, though, CommonFilters implements a bunch of these effects, and we can continue adding to it until we have such a new system.
We’ve thought about handling render effects on the node level in the past, but unfortunately this approach is incompatible with newer graphics APIs like Vulkan; we can’t just switch out which render targets we render to or source from very efficiently in the middle of rendering a scene graph, especially on mobile platforms. Vulkan needs to know ahead of time what the entire pipeline is going to look like.
Note many of the types of effects you list aren’t really comparable, and shouldn’t be conflated into being the same thing, to pick out some examples:
AO, bloom, color correction, etc. are post-processing filters.
Clouds are a particle effect.
PSSM involves rendering the scene depth from the viewpoint of the light several times and integrating the resulting depth maps into the scene shader (combining multiple scene shaders is a very hard problem, by the way)
But I agree with your general point, which is that it would be great to have a modular, pluggable system for effects and filters, one that is more integrated than the RenderPipeline.
Okay, this is the answer I was looking for. It would be nice, but it’s not realistic, not in the next couple months. That’s okay. Can we get a flowchart or something on the internals of the Panda3D engine? These topics are beyond casual conversation and it’s bad if only 1 or 2 people on the planet understand what’s going on with these systems.
We’ll be using the RenderPipeline if we want to make a (rendering) tech demo which is equivalent in quality to the mainstream game engines, if I’m not too much mistaken. I do not want to give up; I believe Panda3D can do these kinds of things with enough finesse and quality workmanship.
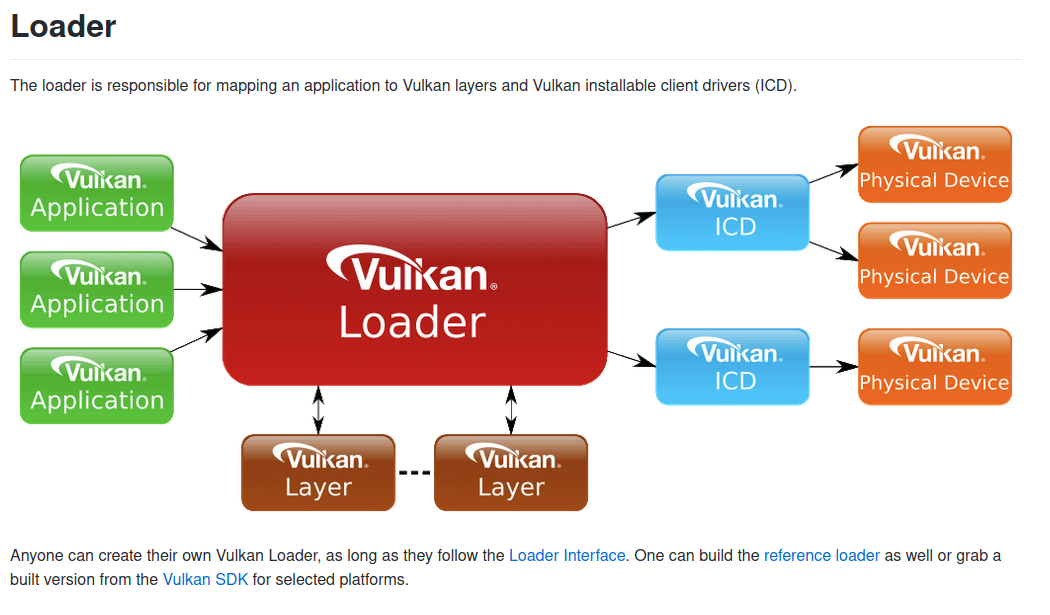
The Vulkan 1.2 spec with extensions is 3,181 pages long. Unreal has a team of engineers working just on integration. Without these well-illustrated Vulkan specs even they would be doomed.
As of the current point, and correct me if I’m mistaken somehow, but as full stack game developers working with Panda3D, the best we can do is to literally read the entire raw source code of our engine to form design opinions on how we proceed with advanced renderer integration.
Was there any thought of merging the render pipeline into the main p3d distros? With all the talk recently of increasing the p3d user base, it’s hard to argue those visuals wouldn’t be a big draw card.
I’d like to, but it seems unrealistic because I cannot understand the entire Panda3D engine + the changes that have been made to the relatively new (like 3 years old) shaderpipeline and vulkan branches of the main distro without documentation of how these systems work.
In lieu of getting (or making) some flowcharts, what I’ll work on practically is figuring out the “final composed form” of the rpcore RenderPipeline shader groupings, and then attempting to make a tiny framework that talks to the internal Panda systems with those hardcoded shader groups in place. I’m not sure that we can even build the bolt-on RenderPipeline at this point into an actual game, and I don’t remember all the various shortcomings (IE it has it’s own, separate, light handling system) that would impact development. I’m not even sure if it supports Hardware Skinning. The last time I used it, threading was disabled by default, and I’ve built a few programs with the threading manually turned back on. But there was probably some (now totally unknown) original design reason for this.
These are some of the reasons I just use simplepbr + customized simplepbr shaders to achieve PBR + Hardware Skinning + an environment that feels “fully native”. It’s not perfect – but it is, at least, fully understandable, and extensible for more shader effects.
There’s a lot of code there, sure. That’s not necessarily a metric for quality however; I’d go back to the idea of how much can be used in a modular fashion and from my (albeit limited) experience with the pipeline, it feels like you either use the entire pipeline holistically or you don’t use it at all.
Incidentally I tried to connect the pipeline to my editor and had some success. There’s some stuff still to work through regarding display regions and built ins, but it shouldn’t be too hard to publish a plug-in that wraps the render pipeline and exposes it to the editor.
If the community is keen to attract more people to its user base, that’s an avenue I’d strongly recommend.
If you are able to build the pipeline into a functioning game demo, with hardware skinning, threading, and the ability to fully compile the demo, that would be interesting.
I would not want the pipeline contained in the official code base, personally speaking. A very different version of it, with roughly the same capabilities, but actually built in the native engine would be fine.
Here is the fully expanded list of “class” in my Arena FPS demo + the entire simplepbr source code directory.
I agree that code size isn’t necessarily an indicator of quality. But from a complexity perspective and a practical perspective, you can probably see why I choose this way.
I think part of the issue is that the current model pipeline is anticipated to be panda3d-gltf, whereas the deferred renderer uses its own exporter (with an incompatible setup, and which is missing some features). So you have to convert one to the other, somehow. That, and it’s a little unfriendly to include due to not being an up-to-date package.
I’ve debated trying to make it use the output of panda3d-gltf, but haven’t actually done that yet.
I think now that we have some PBR-specific texture slots in Panda3D 1.10.8 and panda3d-gltf has been changed to make use of them, we should update the RenderPipeline to make use of those slots as well.