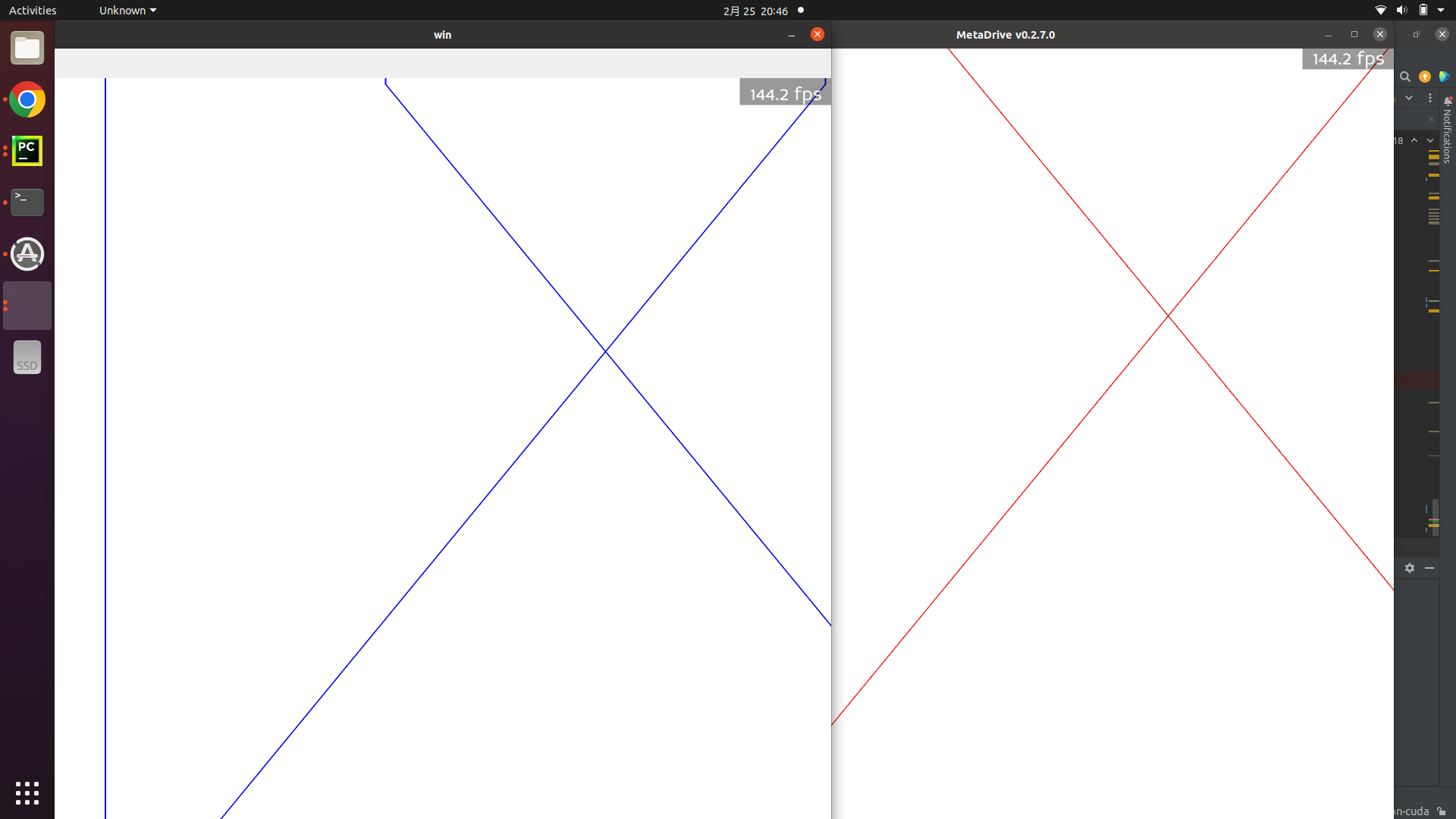
Good News! @rdb
It works! the image read from CUDA memory and the one rendered by Panda are as follows. Ignore th e wrong channel sequence, lol
Here, I would like to share my code. Hope it can help others.
import time
import torch
from torch.utils.dlpack import to_dlpack
from torch.utils.dlpack import from_dlpack
from cuda import cudart
import cv2
import cupy as cp
from panda3d.core import NodePath, GraphicsOutput, Texture, GraphicsStateGuardianBase
import cupy as cp
import numpy as np
from OpenGL.GL import * # noqa F403
from cuda import cudart
from cuda.cudart import cudaGraphicsRegisterFlags
from panda3d.core import loadPrcFileData
from metadrive.component.pgblock.curve import Curve
from metadrive.component.pgblock.first_block import FirstPGBlock
from metadrive.component.pgblock.intersection import InterSection
from metadrive.component.road_network.node_road_network import NodeRoadNetwork
from metadrive.tests.vis_block.vis_block_base import TestBlock, BKG_COLOR
from OpenGL.GL import glGenBuffers
# require:
# 1. pip install cupy-cuda12x
# 2. CUDA-Python
# 3. PyOpenGL
# 4. pyrr
# 5. glfw
#
def format_cudart_err(err):
return (
f"{cudart.cudaGetErrorName(err)[1].decode('utf-8')}({int(err)}): "
f"{cudart.cudaGetErrorString(err)[1].decode('utf-8')}"
)
def check_cudart_err(args):
if isinstance(args, tuple):
assert len(args) >= 1
err = args[0]
if len(args) == 1:
ret = None
elif len(args) == 2:
ret = args[1]
else:
ret = args[1:]
else:
err = args
ret = None
assert isinstance(err, cudart.cudaError_t), type(err)
if err != cudart.cudaError_t.cudaSuccess:
raise RuntimeError(format_cudart_err(err))
return ret
class CUDATest:
def __init__(self, window_type="onscreen", shape=None, test_ram_image=False):
assert shape is not None
self.engine=ShowBase(window_type)
# create your scene
# buffer property
self._dtype = np.uint8
self._shape = shape
self._strides = None
self._order = "C"
self._gl_buffer = None
self._flags = cudaGraphicsRegisterFlags.cudaGraphicsRegisterFlagsNone
self._graphics_resource = None
self._cuda_buffer = None
# # make buffer
# self.texture = self.engine.loader.loadTexture("/home/shady/Desktop/test.jpg")
self.texture = Texture()
# self.texture.setMinfilter(Texture.FTLinear)
# self.texture.setFormat(Texture.FRgba32)
mode = GraphicsOutput.RTMCopyRam if test_ram_image else GraphicsOutput.RTMBindOrCopy
self.engine.win.addRenderTexture(self.texture, mode)
self.texture_identifier = None
self.gsg = GraphicsStateGuardianBase.getDefaultGsg()
self.texture_context_future = self.texture.prepare(self.gsg.prepared_objects)
self.new_cuda_mem_ptr = None
@property
def cuda_array(self):
assert self.mapped
return cp.ndarray(
shape=self._shape,
dtype=self._dtype,
strides=self._strides,
order=self._order,
memptr=self._cuda_buffer,
)
@property
def gl_buffer(self):
return self._gl_buffer
@property
def cuda_buffer(self):
assert self.mapped
return self._cuda_buffer
@property
def graphics_resource(self):
assert self.registered
return self._graphics_resource
@property
def registered(self):
return self._graphics_resource is not None
@property
def mapped(self):
return self._cuda_buffer is not None
def __enter__(self):
return self.map()
def __exit__(self, exc_type, exc_value, trace):
self.unmap()
return False
def __del__(self):
self.unregister()
def register(self):
assert self.texture_identifier is not None
if self.registered:
return self._graphics_resource
self._graphics_resource = check_cudart_err(cudart.cudaGraphicsGLRegisterImage(self.texture_identifier,
GL_TEXTURE_2D,
cudaGraphicsRegisterFlags.cudaGraphicsRegisterFlagsReadOnly))
return self._graphics_resource
def unregister(self):
if not self.registered:
return self
self.unmap()
self._graphics_resource = check_cudart_err(cudart.cudaGraphicsUnregisterResource(self._graphics_resource))
return self
def map(self, stream=0):
if not self.registered:
raise RuntimeError("Cannot map an unregistered buffer.")
if self.mapped:
return self._cuda_buffer
check_cudart_err(cudart.cudaGraphicsMapResources(1, self._graphics_resource, stream))
array = check_cudart_err(cudart.cudaGraphicsSubResourceGetMappedArray(self.graphics_resource, 0, 0))
channelformat, cudaextent, flag = check_cudart_err(cudart.cudaArrayGetInfo(array))
depth = 1
byte = 4 # four channel
if self.new_cuda_mem_ptr is None:
success, self.new_cuda_mem_ptr = cudart.cudaMalloc(
cudaextent.height * cudaextent.width * byte * depth)
check_cudart_err(
cudart.cudaMemcpy2DFromArray(self.new_cuda_mem_ptr, cudaextent.width * byte * depth, array, 0,
0,
cudaextent.width * byte * depth, cudaextent.height,
cudart.cudaMemcpyKind.cudaMemcpyDeviceToDevice))
if self._cuda_buffer is None:
self._cuda_buffer = cp.cuda.MemoryPointer(
cp.cuda.UnownedMemory(self.new_cuda_mem_ptr,
cudaextent.width * depth * byte * cudaextent.height,
self), 0)
return self.cuda_array
def unmap(self, stream=None):
if not self.registered:
raise RuntimeError("Cannot unmap an unregistered buffer.")
if not self.mapped:
return self
self._cuda_buffer = check_cudart_err(cudart.cudaGraphicsUnmapResources(1, self._graphics_resource, stream))
return self
def step(self):
self.engine.taskMgr.step()
if not self.registered and self.texture_context_future.done():
self.texture_identifier = self.texture_context_future.result().getNativeId()
self.register()
if __name__ == "__main__":
win_size = (512, 512)
loadPrcFileData("", "textures-power-2 none")
loadPrcFileData("", "win-size {} {}".format(*win_size))
test_ram_image = False
render = True
env = CUDATest(window_type="offscreen", shape=(*win_size, 4), test_ram_image=test_ram_image)
env.step()
env.step()
start = time.time()
for s in range(10000000):
env.step()
if test_ram_image:
origin_img = env.texture
img = np.frombuffer(origin_img.getRamImage().getData(), dtype=np.uint8)
img = img.reshape((origin_img.getYSize(), origin_img.getXSize(), 4))
img = img
torch_img = torch.from_numpy(img)
if render:
cv2.imshow("win", img)
cv2.waitKey(1)
else:
with env as array:
ret = from_dlpack(array.toDlpack())
if render:
np_array = cp.asnumpy(ret)[::-1]
cv2.imshow("win", np_array)
cv2.waitKey(1)
if s % 2000 == 0 and s != 0:
print("FPS: {}".format(s / (time.time() - start)))
But the texture that the buffer renders into always has a shape (1024, 1024), even if I set the buffer size to (800, 600). I verified this by setting the window size to (800, 600) through loadPrcFileData("", "win-size {} {}".format(800, 600)), and create a texture associated with showbase.win. In RTMCopyRam mode, the texture.getRamImage() is in the same shape as the window size. However, when I change the mode to RTMBindorCopy and use CUDA api to read the texture, the shape is fixed to (1024, 1024), regardless the buffer size is (800, 600). Could you help me figure it out?