Ninth replied in the lens flare thread. He said he’d be happy if the filter was made a part of Panda. As for the license, he said “something like WTFPL or Public Domain” so it’s definitely compatible.
I’ll look into integrating the lens flare as soon as I’m finished with the last-minute inking changes.
I think the rest of the jagginess is probably a limitation of the 1x resolution normal map. The screenshot is basically saying that in the jaggy areas, there is not enough normal map discontinuity outside the “jags” to warrant inking the pixel.
I played around with the settings in my code last night and surprisingly, it turns out that the two “minor changes” seem to have a larger effect on output quality than the subpixel sampling. The subpixel sampling does help visibly (especially in problematic areas), but the half-pixel shift in the discontinuity detector and the use of all three components of the normal already bring a lot of improvement by themselves. I think I’ll make the number of samples configurable, as it affects performance.
That sounds nice.
My inker is a modified version of the inker in vanilla 1.8.1, which also used normals. Also, using the normals plays well with the existing shader generator infrastructure - the currently available textures are the final pixel colour (which in the general case cannot be used for edge detection), the depth buffer (which I think I tested and found useless for inking), and the normal map.
Ah, thanks! Now I see. Looks like the result could be quite nice.
And it indeed seems that this is nearly impossible to do on the GPU, at least unless there is some clever trick I haven’t thought of.
But this gives me another idea. What about if we instead look for short (e.g. max. 5 pixels) horizontal/vertical runs locally near each pixel? The “run length coordinate” would not be available (as it’s inherently a global piece of information), but it would be possible to smooth selectively based on the number of inked neighbours (and their placement).
This would do something like the subpixel inking already does, but ignoring the normal map and just filtering in the pixels neighbouring the generated lines.
It may either look blurry, or useful - I’ll have to test.
Yes.
State could be saved into a new texture in a multipass approach, but I think the actual computation of the desired information is the problematic part, as it relies on stepping along a varying-length run (which is basically a serial approach). Parallelization tends to cause things like this
That’s one possibility I hadn’t thought of. Could be nice. However, it’s a lot of re-engineering and I’m not yet that familiar with Panda, so maybe not for 1.9.0
I look forward to seeing what your experiments produce!
Ah yes–I don’t think that I’ve actually looked at what the Shader Generator does. ^^;
(To be honest, I’m somewhat new at working with shaders; I have some (albeit limited) understanding of their workings, but have very little practical experience in working with them.)
Hmm… That seems as though it could work–I’d likely be worried about all of those texture lookups (if I’m understanding you correctly), but then I imagine that supersampling does something very similar anyway. At the least it does seem worth a shot.
A thought: could it be improved by implementing the run-detection as a binary search? instead of checking each sample point in a given direction, test the maximum distance, and if that’s clear, test halfway to it, and so on. That might allow you to test longer runs than an iterative approach–but I don’t know whether it would be feasible in a shader.
Oh yes, it would be a completely different approach, with a thoroughly different set of components and challenges!
If you want to take a look, the primary shader generator in Panda is written in C++ and resides in /panda/src/pgraphnodes/shaderGenerator.cxx. The interesting stuff happens in the method synthesize_shader(). For cartoon shading, the relevant part is the light ramping.
The postprocessing shader generator is Python-based, located at /direct/src/filter/CommonFilters.py. This generator takes care of the inking step (search for CARTOON_BODY). (In Linux, CommonFilters.py is installed in /usr/share/panda3d/direct/filter/. This is useful for prototyping, as you can simply replace the file and re-run your program.)
When I started this, I found the shader generators rather understandable after reading and puzzling over the source for a while.
Actually, me too. It’s just something that appeared pretty similar to scientific computing
Many of the elements are the same: mathematics (especially numerics and vectorized calculations), algorithm speed considerations (number of operations and memory fetches, degree of parallelism), and the code consists mainly of (sometimes very long and logically unsplittable) functions that are designed to perform one task well. Unlike in application programming, the logic is usually so simple that you can work out just by reading the source code whether a given implementation works correctly or not (resorting to pen and paper for the math).
Still, that leaves a lot to learn regarding things that you gradually pick up by exposure to a particular field - for example, I’d never even imagined a procedural lens flare, until ninth posted his shader and the link where the technique is explained.
(The same blog (http://john-chapman-graphics.blogspot.co.uk/) contains some more useful stuff, including an explanation of SSAO, how to do realtime motion blur, and how to generate good-looking spotlight cones for dusty air. There’s no index, but it’s quickly read through as there are only 7 entries in total.)
The approximate technique used by ninth is a good find, as it’s simple to implement and understand, and it’s computationally light. Another approach to generating procedural lens flares is by raytracing the lens system. See e.g. http://resources.mpi-inf.mpg.de/lensflareRendering/pdf/flare.pdf. The results look very impressive, and the authors mention that the raytracing can be done in a vertex shader, but the article was light on details, so this won’t be at the forefront of my list of things to try
Yes, it will involve additional texture lookups, as indeed does the supersampling. But it might allow for using less supersamples.
In the case of supersampling, it would be possible to eliminate some lookups by placing the supersamples so that e.g. the “right” detector point of one supersample coincides with the “left” detector point of the next one, but that drastically reduces the flexibility of supersample placement and makes the code more complicated. And I’m always worried about using regular grids for sampling (due to potential for moire artifacts).
There are also special tricks that are sometimes applicable. For example, it is good to keep in mind that the GPU does bilinear filtering at no extra cost. Hence, one should keep an eye out for places in the algorithm where a linear combination of two neighboring texels can be used to derive the result instead of using the original two values directly. In the context of gaussian blur, see http://rastergrid.com/blog/2010/09/efficient-gaussian-blur-with-linear-sampling/ (link picked from inside the lens flare link posted by ninth).
If it runs on the GPU, probably not. It’s true that the binary search reduces the run time for one instance from O(n) to O(log(n)), but the branching is likely to destroy parallelism.
A general guideline is to avoid if statements in a shader, as they can be slow in Cl. It wasn’t said explicitly, but I think that implies that the GPU performs SIMD type tasks well, while branching requires extra effort. At least from a vectorization viewpoint that makes sense.
Thank you for the links! There could be some useful stuff in there.
Ah, I see. Well, I look forward to seeing what comes of it.
Ah, fair enough; I’ll confess that some of the restrictions inherent in shaders can be frustrating sometimes (such as discovering that–on my machine, at least–variable array indexing isn’t allowed).
Thank you for pointing out this particular issue, by the way: my pencil shader uses nested if-statements at one point, which I now may want to change.
I’ve now done some more testing, and fixed a mistake in the last version. It turns out the half-pixel shift was erroneous after all. It causes the detector to trigger only at one of the pixels along an edge, which does make it possible to render one-pixel thin lines, but it has a nasty side effect I didn’t notice before.
Sometimes the outline “floats” at a one-pixel distance from the object, or gets drawn inside it (also at a one-pixel distance from the actual edge). Since the upper/lower object outlines exhibit the opposite behaviours, and their behaviours switch when I flip the sign in the half-pixel shift, this implies that the original version without any shifting is correct. I’m almost tempted to provide the shift as an option, since in some cases it produces nice-looking output, but I’m not sure, since in other cases it produces artifacts.
The supersampling is indeed heavy on the framerate. On the other hand, my GPU is an old Radeon HD 2600 Pro, which is very slow by today’s standards (and running on the even slower open source drivers since the official drivers no longer support it), so the inking may run at decent speeds on more modern hardware.
Comparing by flipping through the images in a viewer, the improvement from the oversampling is significant. I’ll post some screenshots in a separate post (3-attachment limit).
In any case, this means I’m adding an “inking quality” configuration parameter to the final version. (That may be clearer than num_samples, sample_threshold, use_depth_buffer, enable_postprocessing, …)
Also, experimenting with implementing the inker as either inlined into the main postprocessing shader (writing to the final output directly) or as a separate shader rendering into its own texture (and then a couple of lines in the main shader applying the ink texture), the separate pass costs a few fps at least on my machine. But it buys flexibility, since postprocessing for the outlines is not possible if the ink is drawn directly onto the final output.
Multipassing has also some other consequences. It makes the ink separately viewable in BufferViewer (which is nice for debugging); and makes it incompatible with the blur filter, which sees only the colour texture from before any postprocessing filters are applied. But this is an issue in the current design of CommonFilters; it was there already for any multipass filter in 1.8.1. It seems that to do this kind of things properly, CommonFilters needs some sort of mechanism to construct a multipass shader (maybe based on some kind of hardcoded per-shader priority index to determine in which order to apply the filters). I might look into this, but that’s after 1.9.0.
I’m still working on the ink postprocessor. Will try to get it done this weekend. Notes to self:
Idea to be tested: in order to add any smoothing ink to a pixel, inked neighbours should already exist along at least two different rows/columns in the stencil. This avoids widening straight horizontal or vertical runs (otherwise pixel row/column aligned runs would bleed). However, it does also affect the look; hence, to be tested.
If there are no inked neighbours, or at most one, the original ink pixel should be discarded (and no smoothing applied) to avoid pixel-size ink spots in the output.
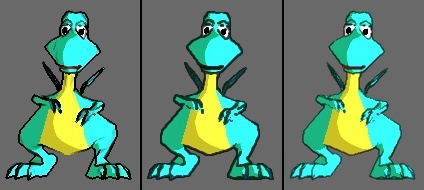
It also occurred to me that while the depth buffer by itself is almost useless for inking, it is a useful secondary data source for edge detection. It is good especially for object outlines, and for edges where parts of the same object at different depths have nearly identical normals, as shown:
In the vanilla 1.8.1, note missed internal edge where the tail meets the body. Observe also that the new version detects all the outlines of the dragon.
The drawback is that this kills the framerate even more, because now there are two input textures that both need edge detection with supersampling. But at least now the filter picks up most of the previously remaining missed edges. The only other data sources I can think of are genuine object outlines (maybe not needed, the depth buffer is already pretty good for this?), and material interface edges, both of which require changes to the primary shader generator to generate the necessary auxiliary textures. Currently, only one aux texture is supported, so this may also require some other changes to the infrastructure…
(Indeed, the inker in Blender3D uses several different data sources to find the edges, so I think this hybrid approach is probably correct to obtain high-quality inking.)
All screenshots in this post taken using the new version. Depth buffer is used as an auxiliary data source.
The depth buffer is also used to slightly modulare the separation parameter (changing the thickness of the line depending on distance from camera), but I might still tweak this. Due to the nature of the algorithm, separation does not really control line thickness: instead, it controls the radius of the edge detection stencil.
Up to one pixel of separation, these are effectively the same thing, but above one pixel, it also displaces the outline from the pixel containing the edge, because the edge is detected from further away. An object that is thinner than the separation value may get several non-overlapping “ghost” outlines. (This is a consequence of the inking algorithm, and was there already in 1.8.1.)
The only difference between the pictures in this post is the number of subpixel samples. Look at the top of the head to see the effect clearly.
Sometimes limitations like this can be worked around. For example, many older GPUs (mine included) do not support variable length for loops (the Cg compiler wants to unroll loops, and cannot if the end condition depends on a variable).
If you have a shader generator, and the loop’s end condition uses a variable just because it depends on a configuration parameter (which remains constant while the shader is running), you can make the shader generator hardcode it from its configuration when it writes the shader. If you’re coding your application in Python, Shader.make() (from pandac.PandaModules) comes in useful for compiling shaders generated at runtime. Look at CommonFilters.py for usage examples. But of course doing this adds another layer of logic.
Also, keep in mind that error messages from Cg can sometimes be misleading. I encountered the variable length for loop problem when I was trying to figure out why Panda’s SSAO wouldn’t run on my GPU. I was debugging entirely the wrong thing until rdb stepped in, said he’d seen a similar situation before, and that it is likely the problem is in the variable-length loop, not the array it is indexing into (although the error message indicated that the problem should have been in array indexing).
(SSAO is fixed in 1.9.0, using the approach mentioned above.)
Just after I said that, I did some testing this evening and found that the following run at the same speed on my GPU:
the alternatives still ran at the same speed. Of course, this test is hardly conclusive; the texture lookups in the supersampler are probably taking so much time that a single if statement (or two) has a negligible effect on the total time taken by this particular shader. But that’s also a useful piece of information: branching is not always a total performance killer.
I also observed that the Cg compiler, at least as invoked by Panda, seems to optimize the code (which is of course the sensible thing to do - what is not clear a priori is whether there is an optimizer in any given compiler, and if so, what kinds of optimizations it applies).
The optimizer seems pretty advanced - it seems to do some kind of dependency analysis and omit code that does not affect the output. (I was trying to do a rudimentary kind of manual profiling of the shader, disabling parts of it to see what is taking the most time.)
Namely, even if the shader code analyzes both the normal and depth textures, there is absolutely no speed impact if it does not use the result (filling o_color with a constant value). The expected performance hit from the texture lookups appears immediately when the result of the calculation is used in computation of o_color. I disabled the if statement and the lerp, too, using just “samples/NUMSAMPLES” to set the red component of o_color, setting the other components to constant values. The result was the same.
In conclusion, it might be good to test your particular case using both the nested-if and branch-free approaches, if the branch-free version is not too complicated to write.
Regarding the new version: I do think that it’s an improvement over the 1.8.1 version–the reduction in missed edges alone is enough to make it a worthwhile inclusion, methinks.
One thing that I notice: the edges in the new version seem to be a lighter colour than in the 1.8.1 screenshots–is that intentional?
Hmm… Looking at the lines, the jaggedness of the edges does seem reduced. Looking closely, the antialiasing pixels seem a bit light–could they be deepened a bit, to make the antialiasing a little stronger?
I don’t think that this will likely help in my case–as you mention a little further on in your post, there’s a variable-length loop involved. In short, I was experimenting with using a count of sample colours (which are effectively object ids in my implementation, recall) when detecting edges in order to antialias my lines somewhat–the idea being that a point the samples of which are heavily biased towards one colour or another is presumably further from the edge than one that has a nearly even distribution, and can thus be rendered as “partially-inked”, hopefully shading the line a little.
Hmm… Perhaps… I might go back and have another shot at a non-if version (the nested-if version replaced a non-if version that wasn’t working); it will likely be cleaner, at any rate.
This code is pasted by the generator into the fshader if inking is enabled.
Some notes. Here l_texcoordN is initialized based on vtx_position.xzxz (in the vshader), so it contains the same coordinates twice. The parameter k_cartoonseparation is a float4 with the first and third components nonzero. Note the .xwyw applied to texpix_txaux. Finally, observe that in the computation of each cartoon_c*, the last two components of the corresponding cartoon_p* are discarded (accessing it by .xy). Combining these observations, the .wzyx is a trick that, given this setup, allows using the same delta variable to offset in the y direction (used as .xyzw it offsets in the x direction).
As for the colouring, observe the last two lines of code. The saturate() clamps between 0 and 1, but does not touch values already in that range, leading to a sort of shading as the value of the expression varies. However, as can be evidenced by changing the relevant line to
this is actually the culprit behind the “reversed smoothing” in the side bangs in the original vanilla 1.8.1 screenshot that I posted earlier. The normals don’t always behave in the way this code assumes!
Also, the float4(3,3,0,0) is the reason for some of the missed edges; float4(2,2,2,0) would be better, as the normal is a 3D vector. But I have to admit that in my modified version, I went for float4(1,1,1,0) and changed the cutoff (0.5) to 0.3. This seems to produce the best results out of the combinations I have tested.
End EDIT.[/i]
The supersampling (subpixel) version uses the number of supersamples that would like to have the pixel inked to control the alpha value. The control is scaled so that the voting threshold corresponds to zero alpha, and when all supersamples agree, the alpha becomes 1.0.
Hence, unless all supersamples agree, the ink pixel will be partially translucent. Thus the line will in general be lighter.
At the same time, it is of course this exact same property of the supersampling version that produces the smoothing.
Yes. It’s just a matter of inserting a suitable mapping function to the alpha control. The difficult part is figuring out what is a good shape for the function
(Maybe a fractional power such as sqrt, as they are commonly used to boost the low end when values are in the range 0…1.)
But before experimenting with that, how about this version (finished over this morning’s coffee)?
Now the supersampler is off, and instead postprocessing is used.
This is my modified pixel-local version based on your “detect runs” suggestion to line smoothing. It is designed to detect certain patterns of 2 and 3 inked neighbours (so at most it applies a two-pixel “run” of smoothing).
It runs a lot faster than the supersampling version, requiring 12 additional texture lookups in the ink texture, for a total of 4*2 + 12 = 20 texture lookups per pixel. Here the first term comes from the first pass; 2 = number of textures to process (normals, depth); 4 = number of detection points.
Compare to the 9 x supersampling version, which requires 9 * 4 * 2 = 72 lookups.
Also, the smoother requires no parameters.
If both are supersampling and postprocessing are active at the same time, the result looks fuzzy:
The fuzziness comes from smoothing pixels that are only partially inked. The algorithm already factors in the alpha values of the original inked pixels, so it may be that there is simply no need to postproc-smooth in places where there are already translucent pixels. Some additional logic could probably fix this (e.g. by switching off smoothing locally below a critical alpha), but I’m not sure if there is a point in doing that.
So it seems we have two options to smooth the lines - either supersampling (costly, but can produce thin lines; works down to separation = 0.5) or postprocessing (relatively cheap, but lines always look thicker; starts breaking down if separation < 0.7).
I’m rather tempted to support both, making the cheap postproc the default.
I see. Well, too bad
By the way, one more link - if you haven’t already read the Cg documentation http://http.developer.nvidia.com/Cg/index.html, it contains some useful information. There’s of course API documentation on the stdlib functions, but also the listing of profiles is useful.
For example, many shaders in Panda use the arb_fp1 profile. The documentation for this profile says that variable-length loops are not supported, because the profile requires all loops to be unrolled by the compiler. Maybe I should have read that first a year ago
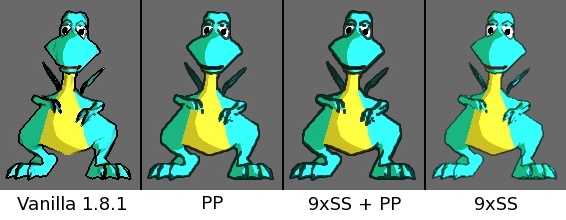
If the object being rendered is far away from the camera (which may often be the case in e.g. 3rd person games), then supersampling gives visibly better quality than the cheap postprocessor. Here’s a screenshot at 1:1 resolution, with the camera placed at (0,-150,0) instead of its original position at (0,-50,0) (used in the previous screenshots):
Left: vanilla 1.8.1 Center: new inker, using postprocessing Right: new inker, using 9 x supersampling
One thing that I’ll say against it is that it doesn’t seem to handle the eyes–the pupils in particular–quite as well as did the super-sampled version, I feel. I’m not quite sure of what’s going on there, but the post-processed version leaves that little white section somewhat square, and there seems to be a line being generated at the top of the pupil that the supersampler is perhaps handling a little better–even if it’s just by virtue of making it harder to spot.
I… Actually prefer the centre image–the post-processed version–I believe. While I can see that one might want the thinner lines of the right-hand image, the thick lines of the centre version given the result a nicely cartoony feel to my eye.
I think it’s because the postprocessing version is basically taking a slightly improved version of the vanilla render (i.e. the version generated by the new inker without supersampling), and then inking additional pixels on top of that.
Without supersampling, the edge detection is not as accurate, so the input to the postprocessor is not very good. The postprocessing still removes the “jags”, but due to the inaccurate detection of the more difficult edges, it will cause some areas to fill where they shouldn’t.
The eyes of the dragon model are especially problematic. I think these edges can be detected reliably only by looking for material discontinuities; there is not enough variation in the normals or in the depth. (The same applies to the side bangs in my own test model.)
To fix this, it might be possible to use the supersampler also in the postprocessing-based version, in order to get more accurate edge detection. As my test shows, this obviously needs some changes to the logic that decides the colour of the original inked pixels; maybe they all need to be rather dark for the postprocessor to work properly without causing a fuzzy look.
There is also a related issue: this type of postprocessing cannot vary the thickness of the line based on the distance of the object from the camera. It will always cause the line to look approximately two pixels thick. Thus, as the dragon gets further away from the camera, a larger relative proportion of the white area in the eyes will be filled with ink.
This implies also that when the camera (or the character) moves in the depth direction, the change in relative line thickness (w.r.t. the size of the character on screen) becomes very noticeable. If this is the intent, then that’s fine - but I find I personally prefer a version that tries to keep the relative line thickness approximately constant for moderate to far zoom levels.
One further idea: it would be possible to extend the line detection by one more pixel in a rather simple manner, by introducing another 12 texture lookups. The key observation is that if a line steps onto this row/column N pixels away (along either coordinate axis), the other N-1 pixels belonging to the line must be on a neighbouring row/column. For N >= 2, three new pixels are needed per cardinal direction, leading to a total of 12. But I’m not sure if the extra cost is justified - two-pixel fades to smooth out the “jags” already seem to work pretty well.
Ah! Thanks for the input! Yes, it’s the post-processed version.
I’m aiming for an anime look, and I think the supersampling version approximates that better, especially when a character covers only a small part of the screen (as is common in platformers, strategy games, …).
But it is good to have the option for a different kind of cartoon look, too - especially in a general-purpose library such as Panda.
Aah, fair enough–that does make sense: while I’m not sufficiently familiar with anime to comment on that, I feel, I do see that thick lines would likely be a bit of a problem in cases in which objects typically cover only a small part of the screen.
The reason is of course that the line is already at least one pixel thick and is completely black. The postprocessing spreads more ink (into previously non-inked pixels) to smooth out “jags”. Hence, a pixel-aligned line in a 45 degree angle will look approximately two pixels thick. Lines nearer to horizontal or vertical directions will look between one and two pixels thick.
The supersampling is able to represent lines of varying thicknesses, because it can compute the fraction of the pixel covered by the detected edge.
Though I have to admit that when I paused to think about it in more detail, I don’t fully understand why the supersampling works so well.
After all, this is a postprocess filter working on fullscreen textures, which gets a 1x resolution normal map as its input, so the input contains no actual subpixel data. When asked for normals at some fractional location that is not a pixel center, the GPU just bilinearly interpolates between the normals captured at the nearest pixel centers (i.e. the values in the aux texture).
It is clear that in areas where a quantity is continuous, its (bi)linear interpolant is often a pretty good approximation, when the set of actual source data points is dense enough compared to the space rate at which the quantity changes.
[i](Arguably, though, in the case of normals, the most accurate interpolation is spherical linear interpolation (a.k.a. slerp, quaternion rotation) instead of the regular kind, because the normal represents a direction. In this case, regular linear interpolation can be seen as an approximation, which works reasonably well only if the change in the normal over a pixel is small enough. Using regular linear interpolation between two unit direction vectors, the interpolated vector won’t even be of unit length, because (as the convex combination parameter varies from 0…1) the interpolated vector’s tip moves in a straight line, instead of following a great circle on the unit sphere.
It is, however, a non-trivial question how the kind of interpolation used affects the edge detector. It may happen that the current edge detection algorithm works better with the regular kind of interpolation, although it is the “wrong” kind.
So this is primarily a theoretical aside one should be aware of; since the inker already works, and regular lerp is supported in GPU hardware, there is really no reason to switch the interpolation of normals to slerp.)[/i]
The next thing to observe is that linear interpolation without any special handling for jumps always produces continuous interpolants. Discontinuities are automatically eliminated.
Furthermore, to be mathematically accurate, it should be pointed out that because the input is a texture - i.e. discrete sampled data that is only defined at the grid points - the input itself contains no information whatsoever about what happens between the sampled points (strictly speaking, it doesn’t even claim anything exists there). Linear interpolation is just a particularly convenient choice for the operator that is used to “promote” (in the computer programming sense of the word) the data from discrete sampled points on a grid into a function of x and y.
Then there is the design of the detector. The edge detector, as it is currently implemented, basically has an arbitrary threshold for the maximum allowed jump of a “continuous” quantity over one pixel, and if the detected change exceeds that, then it declares a discontinuity (i.e. an edge).
Some of the supersamples clearly read data from both sides of the edge (now understanding “edge” as where a human would declare it to be), while some may read only on one side of the edge (maybe this causes the lighter shade of ink?). The most peculiar category are those that read the linear interpolant from the halfway point between the pixels.
This is the point where intuition stops helping - I suppose if I wanted to look more closely into this, I should write out the equations for a simplified 1D case to figure out what is going on.
I’ll support both - it is good to have flexibility in a general-purpose library.
In this variant, 9 x supersampling is used to determine edge locations. In the first pass, all pixels passing the voting test are inked fully black, and in the second pass the postprocessor is applied to do the smoothing.
Here are the results. Again 1:1 size to show artifacts: